Adding texts to Tesserae’s searchable database requires ensuring that every line has a human-readable locus associated with it. Checking through Perseus TEI and selecting one, consistent numbering system to apply to all the lines of a text is no easy job—as James and his team of interns will readily attest.
One way in which this might be made easier is processing similarly-structured texts in batches. But TEI is flexible enough that texts with the same structure in print (e.g. Book–Poem–Line, or Book–Chapter–Section) don’t necessarily have the same XML structure. To take a simple example, some poetic texts enclose each line in <l> tags, with line numbers coded as attributes of the line elements, as in the case of Ovid’s Metamorphoses:
<l>In nova fert animus mutatas dicere formas</l>
<l>corpora; di, coeptis (nam vos mutastis et illas)</l>
<l>adspirate meis primaque ab origine mundi</l>
<l>ad mea perpetuum deducite tempora carmen.</l>
<l n="5">Ante mare et terras et quod tegit omnia caelum</l>
<l>unus erat toto naturae vultus in orbe,</l>
<l>quem dixere chaos: rudis indigestaque moles</l>
<l>nec quicquam nisi pondus iners congestaque eodem</l>
<l>non bene iunctarum discordia semina rerum.</l>
Other texts encode the same structure by interspersing numbered line breaks throughout a block of text, as in Silius Italicus’ Punica:
<lb rend="displayNum" n="1" />Ordior arma, quibus caelo se gloria tollit
<lb rend="displayNum" n="2" />Aeneadum, patiturque ferox Oenotria iura
<lb rend="displayNum" n="3" />Carthago. da, Musa, decus memorare laborum
<lb rend="displayNum" n="4" />antiquae Hesperiae, quantosque ad bella crearit
<lb rend="displayNum" n="5" />et quot Roma uiros, sacri cum perfida pacti
<lb rend="displayNum" n="6" />gens Cadmea super regno certamina mouit
<lb rend="displayNum" n="7" />quaesitumque diu, qua tandem poneret arce
<lb rend="displayNum" n="8" />terrarum Fortuna caput. ter Marte sinistro
<lb rend="displayNum" n="9" />iuratumque Ioui foedus conuentaque patrum
<lb rend="displayNum" n="10" />Sidonii fregere duces, atque impius ensis
<lb rend="displayNum" n="11" />ter placitam suasit temerando rumpere pacem.
When it comes to automatically adding the correct locus to each line of text, these two encodings demand different treatments, as in one case the line number is an attribute of the parent element, whereas in the other the line number is an attribute of a sibling.
I thought it might be interesting to see whether we could automatically classify texts based on the type of XML tags used in encoding them. This could identify which texts would need similar treatment without making assumptions based on the way the print texts were structured.
I decided to try a rough classification of documents based solely on what kinds of nodes they contained and the hierarchical arrangement of those nodes. For example, you can guess which of the following paths occurs in Cicero’s Letters to Atticus, and which in Plautus’ Menaechmi:
TEI.2/text/body/div1[@type='book']/div2[@type='letter']/opener/salute
TEI.2/text/body/div1[@type='act']/div2[@type='scene']/sp/speaker
I generated a list of all unique paths from root to leaf in each text. I only kept attribute values in two cases, the @type of <divn> and the @unit of <milestone>. This is because important information about the structure of the text may be in the attributes here.
In this first experiment I didn’t even bother considering how many instances of each path a text contained; I just set the feature to 1 if the path was present and 0 if not. Each text was ultimately represented by a vector of 1095 binary features, one for each of the unique paths that occurred anywhere in the corpus.
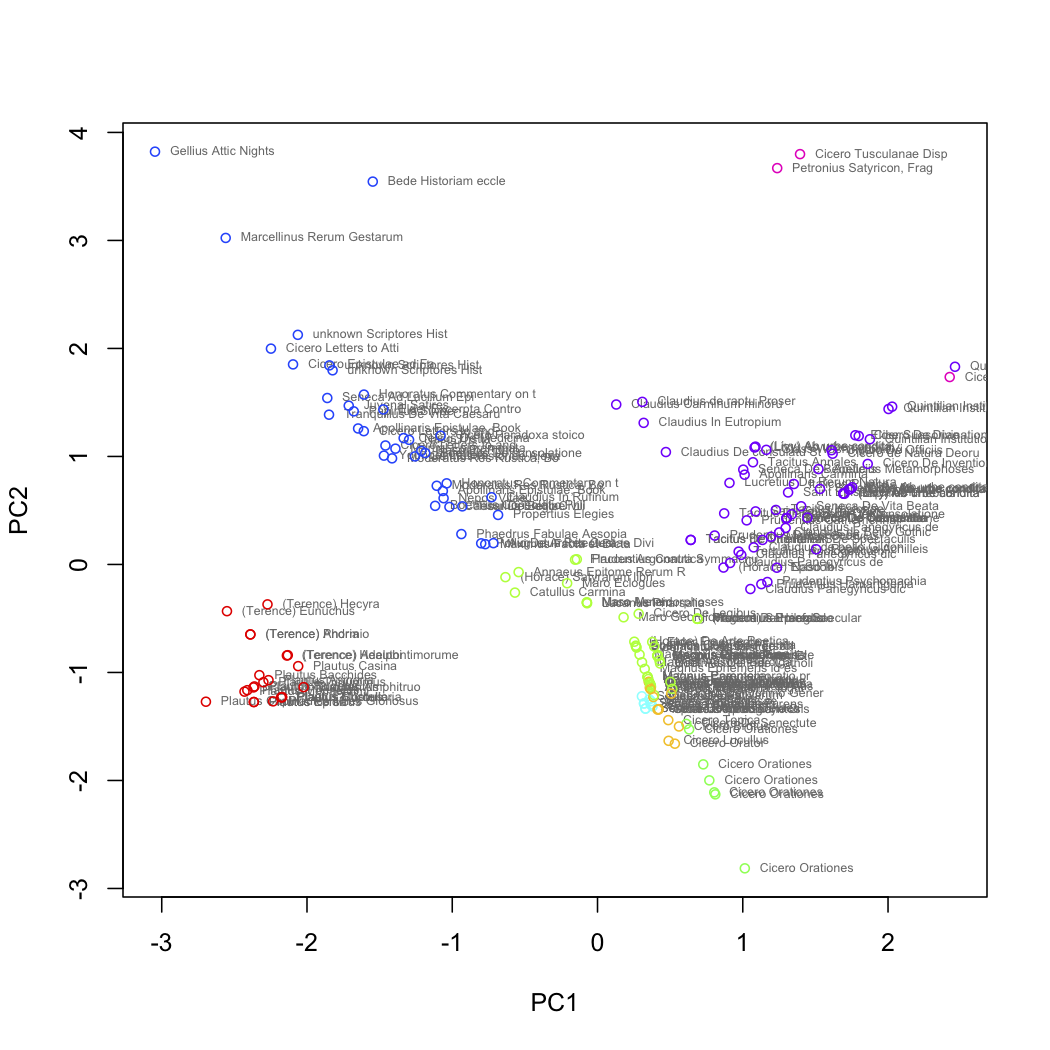
Here we see the texts represented by the first two principal components of those feature vectors. The points have also been colored according to an independent, k-means classification of the original vectors into 8 classes.
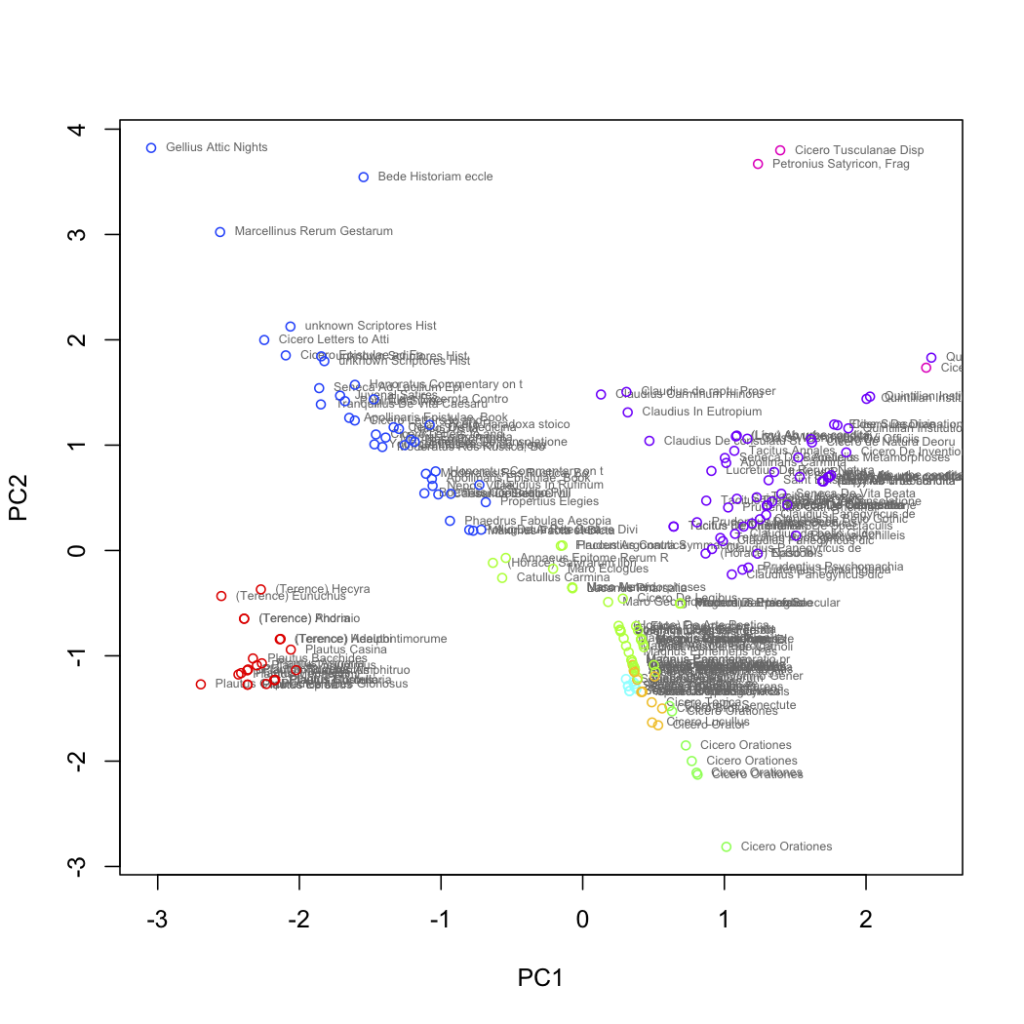
For me, three things jump out immediately: first, that drama is set apart from all the other texts; second, that Cicero manages to cover almost the entire feature space; third, that the remaining genres do cluster, but overall tend to show a gradient of characteristics.
Even as we continue to work on a universal text-parsing tool, this line of investigation could potentially speed the addition of Perseus texts. I think the next step will be add information about who edited the digital text to the feature vector. This will help move classification from primarily genre-driven, identifying differences we could have predicted, to include TEI coding idiosyncrasies such as the difference in line numbering illustrated above, which we wouldn’t have been able to guess without examining all the files by hand.