When Augustine quotes portions of Paul’s epistles in De Doctrina Christiana 4, he records versions that are not attested by the Vulgate tradition or the Old Latin (Versio Antiqua) tradition. Since Augustine quotes closely from the Vulgate, (and sometimes from the Versio Antiqua), for Gospel and Old Testament passages in DDC 4, why not for Paul’s epistles? My data suggests that these Pauline passages, which appear as examples of style rather than content, are in fact rendered in a more Ciceronian style than alternative translations.
The Pauline passages are a mosaic of Vulgate and Versio Antiqua renderings, mixed with variations that have no authority in either manuscript tradition. Variants are sometimes semantic changes, and at other times simply change the rhythm of the prose – an element of style Augustine is very concerned with (DDC 4.41). The following are examples taken from the first extended Pauline quotation (2nd Corinthians 11:16-31) in DDC 4.12:
- DDC: Toleratis enim si quis vos in servitutem redigit
- Vul: Sustinetis enim si quis vos in servitutem redigit
- VA: Suffertis enim si quis vos in servitutem redigit
- DDC: Si gloriari oportet in iis quae infirmitatis meae sunt
- Vul: Si gloriari oportet quae infirmitatis meae sunt
- VA: Si gloriari oportet quae infirmitatis meae sunt
Below are links to visual comparisons powered by Juxta Commons of Paul’s language as it appears in De Doctrina Christiana, and Sabatier’s Vulgate and Versio Antiqua, and exemplary passages from Psalms and Matthew. There are four options to visualize the differences: a heat map with hyperlinked variants, a side-by-side comparison, a histogram, and a VM model where all three versions can be viewed side-by-side (click “new version” after clicking on the VM button).
2nd Corinthians 11:16-31 – Augustine’s first example of Paul’s eloquence
Galatians 3:15-22 – Augustine’s example of the subdued style
Romans 12:1, 6-16; 13:6-8, 12-14 – Augustine’s example of the moderate style
Galatians 4:10-20 – Augustine’s example of the grand style
TEI markup of all textual variants: 2nd Corinthians (first) Galatians (subdued) Romans (moderate) Galatians (grand) Psalm 15-4 Matthew 10-19-20
While it is immediately clear that the Pauline passages show more variations than non-Pauline passages, it is difficult to get a sense of the degree of difference because the passages differ so severely in length. Juxta Commons, however, provides an quantitative measurement of distance from a base text to other versions. The graph below shows Juxta’s measurement of distance between the above passages as they appear in DDC and in the Vulgate / Versio Antiqua. The baseline drawn at 0.05 is the distance Juxta measures between Sabatier’s Vulgate and the Vulgate available on Perseus. It provides a sense of what degree of difference we might expect between manuscripts.
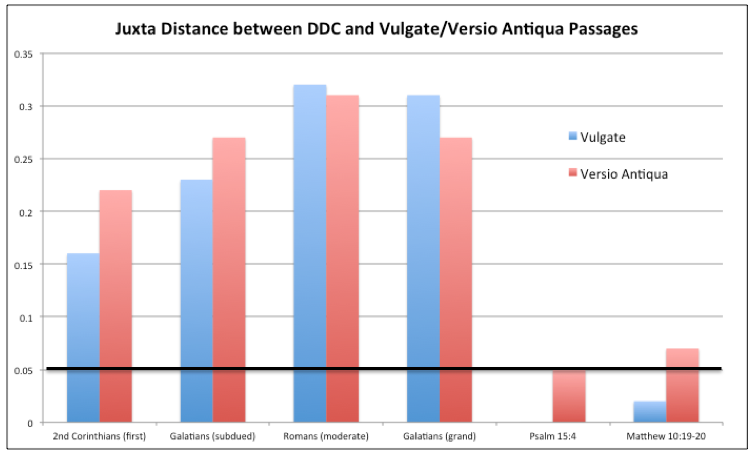
This degree of difference demands explanation. The Pauline passages appear as block quotations, discouraging the interpretation that Augustine is weaving in his own language, as is often the case in his other works, in an extemporaneous style. These passages are not tied together thematically, but appear as distinct units with little or no connective language. It is also notable that Pauline diction appears in De Doctrina Christiana as models of style. Augustine argues at length that even though Paul was untaught in the classical rules of rhetoric, his eloquence displays the qualities of classical rhetoric such as climax, scala, and well-balance membra and caesa (DDC 4.11). He follows his quotation of many Pauline passages with extended colometric analyses, drawing on Cicero’s rhetorical metaphor of the body established in Orator, and continuing in DDC 4 to outline the officia oratoris and the genera dicendi according to Cicero’s model.
Given the extreme level engagement with Cicero in DDC 4, noted consistently in scholarship, might Augustine have chosen to deviate from the Vulgate and Versio Antiqua versions in order to present a more Ciceronian version of Paul in Latin? Whether Augustine quotes this passage from a manuscript no longer extant, or makes editorial choices of his own, Tesserae can lend an objective measurement to traditional stylistic analysis. The following Tesserae results are from my stylistic experiment to compare the three versions of 2nd Corinthians – Augustine’s closest rendition of Paul to the Vulgate / Versio Antiqua tradition – to the entire Ciceronian corpus. Notice that Augustine’s presentation of Pauline diction finds more instances of shared language that that of the Vulgate or Old Latin version. (For a full explanation of the search parameters that target style, rather than allusion, see below at “Explanation of Search Parameters.”)
Ciceronian corpus vs. 2nd Cor. in DDC
Ciceronian corpus vs. 2nd Cor. in Versio Antiqua
Ciceronian corpus vs. 2nd Cor. in Vulgate
*NB Tesserae expects to display results from one source text, but Cicero’s corpus includes many texts in one file. Tesserae only displays the location information for Cicero according to its initial processing. To find the location of a Ciceronian match, simply search for the exact string of characters in from the above results in cicero.corpus_1.tess cicero.corpus_2.tess. (The file is split into two parts so as not to exceed upload capacity; copy and paste cicero.corpus_2 into cicero.corpus_1 for the full .tess file.)
Examples of matches:
- DDC: quoniam quidem multi gloriantur
- Cicero Tusc. 3.66: quoniam quidem res in nostra potestate est
- DDC: Iterum dico ne quis me existimet
- Cicero Ver. 2.5.9: ne quis emeret nisi in demortui locum
These results are not particularly meaningful by themselves, but the composite of all the possible results like this is key component of style.
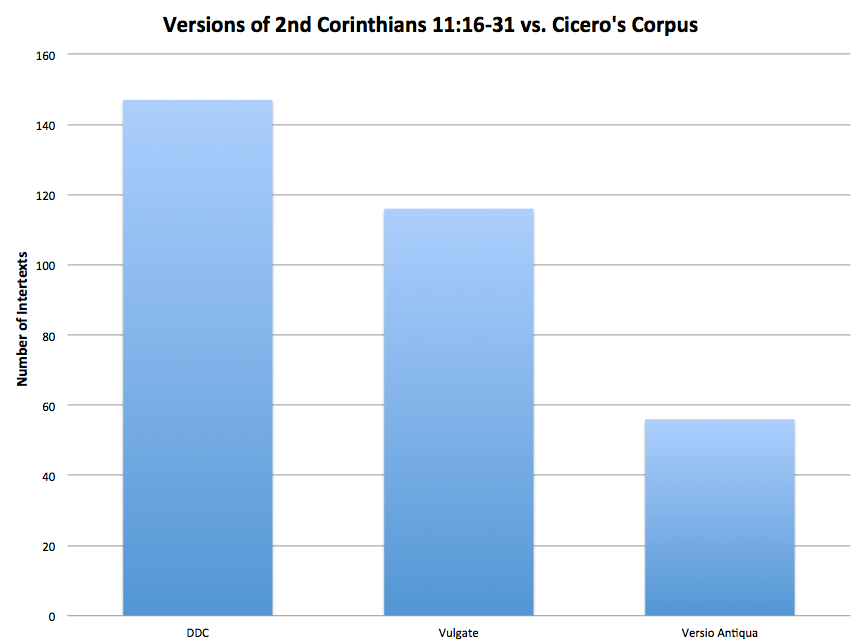
This graph displays the total number of times Tesserae found a set of match-words in Cicero’s corpus shared by each version of 2nd Corinthians. Thus the first column shows the total number of times Tesserae found one to four word chunks in the same position relative to each other in DDC and Cicero’s corpus. No similar pattern emerges from the same three passages tested against the corpora of Caesar, Tacitus, or even against another rhetorical work, Quintilian’s Institutio Oratoria. (Compare here: CaesC DDC CaesC VA CaesC Vul; Q DDC Q VA Q Vul; TC DDC TC VA TC Vul.) This suggests that Augustine’s translation does not intertext more frequently with classical works generally, and suggests that Augustine’s presentation of Paul’s language is indeed more “Ciceronian” than other Latin translations.
Support for this method of stylistic analysis:
For centuries, Lactantius has been called “the Christian Cicero.” Jerome ascribes to Lactantius “Tullian eloquence” (Ep. 58.10), developed by Pico della Mirandola as “Ciceronem sed Christianum.” Even in the present day authors argue that Lactantius deserves this title due to the form and elegance of his language. Tertullian and Justin, other early late antique prose authors, receive no such recognition – in fact, their styles are often disparaged even though their works were extremely popular. Tesserae is able to capture this difference in style. Lactantius’ De Mortibus Persecutorum intertexts with Cicero’s corpus at a much higher rate that similarly sized selections from Tertullian’s Apologeticum and Justin’s Epitome:
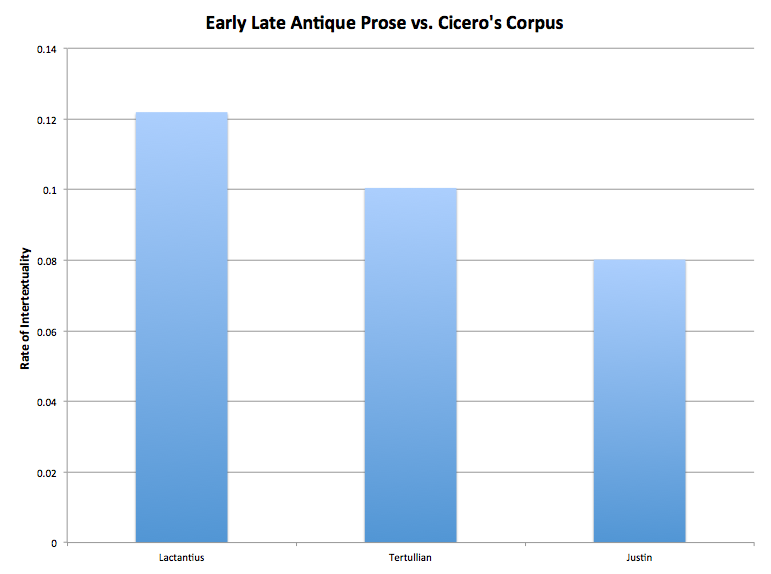
(This graph displays the rate of intertextuality rather than number of intertexts since these large selections must be normalized by number of phrases. Rate of intertextuality = {number of Tesserae results / (Number of source text phrases * Number of target text phrases)}
This stylistic measurement remains consistent even when very small chunks of texts are compared to Cicero’s corpus. Following are Tesserae comparisions of small selections chosen at random from Lactantius, Tertullian, and Justin, each about the same size as 2nd Corinthians 11:16-31.
CC Justin small CC Justin small2 CC Justin small3
CC Lact small CC Lactantius small2 CC Lactantius small3
CC Tertullian small CC Tertullian small2 CC Tertullian small3
Averaging these results, we find that Lactantian language even at a small scales intertexts with Cicero’s corpus much more than that of Tertullian or Justin:
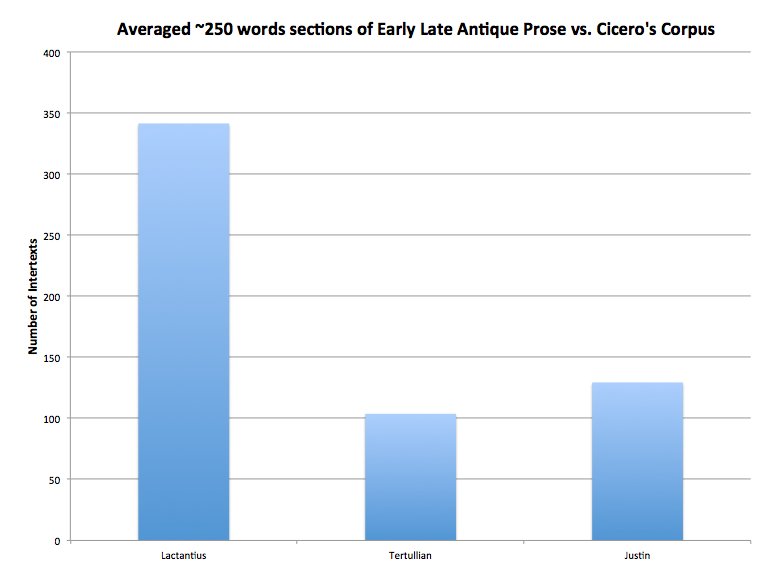
This method supports the observations of ancients and scholars to this day who call the style of Lactantius Ciceronian. Such stylistic analysis can be used on other texts, like Augustine’s translations of Pauline diction, with greater confidence.
Future goals for this project include testing hundreds small sections of Lactantius, Tertullian, and Justin (and other authors) against Cicero’s corpus to get a more stable average. This will allow me to add meaningful error bars to the above graph and be more confident in the significance of an author matching Cicero “twice as much” as another.
Explanation of Search Parameters:
The search parameters used in these Tesserae comparisons are very different from the pre-set options geared towards finding possible instances of allusion. My searches use the following parameters:
–unit phrase This makes a Tesserae search divide units of speech by phrase, rather than by line. This option should be chosen for all prose text comparisons.
–dist 4 This constricts a Tesserae match to words that have two or fewer intervening words. The normal parameter is 10, allowing words to match across lines of poetry or across long clauses in prose. It’s important for a stylistic search to look only for words that appear very close to each other, rather than words that might constitute a element of intertextuality across a long distance. For comparisons with much smaller corpora, such as the texts of 2nd Corinthians compared to Caesar’s corpus, I widened the dist metric to 6. This includes a few more matches and provides a more stable measurement for otherwise very sparse results.
–stop 0 This allows Tesserae to search for matches that include every word in the corpus. Usually this parameter is set to 10, which excludes the top 10 most common words in search texts from results. This is helpful for eliminating results in an allusion search, where the user probably won’t want to examine results including qui, sum, et, in, etc. For a stylistic search, however, it’s extremely important to include all words, developing a composite of all the combinations of words that make up an author’s style rather than unusual or salient instances that might be allusions.
–feature word This instructs Tesserae to search for exact word matches rather than matches based on shared stems, or lemmata. Whereas an allusion might contain shared lemmata in different forms depending of local grammatical restraints, exact word matching allows Tesserae to capture elements of style like a tendency towards accusative + infinitive, a preference for a particular tense of a verb, etc. This kind of matching is much more precise for stylistic analysis.
A note on phrase-based searching:
While many other stylistic measurement exist, Tesserae is unique in measuring shared language in the context of an author’s phrase (delimited by periods and colons). Tesserae also looks not only at word frequency, but at the relative position of sets of words to each other in phrases. This helps Tesserae capture style in ways that corpus word frequency measurements do not.
I welcome comments and suggestions at acstaab@buffalo.edu.