
Measuring the co-occurrence patterns of words with pointwise mutual information (PMI) can help identify bigram word-pairs that are unusually represented in the work of a given author. By comparing the PMI values of the Latin epic corpus to the PMI values of Vergil, for example, scholars can discover which word pairings are particularly Vergilian. Many of these Vergilian phrases will be obvious, such as pius Aeneas and puer Ascanius. Others, however, invite further investigation. Some word pairings are so unexpected that they may be sufficiently marked for quotation and imitation.
Tesserae is in the process of incorporating PMI data as an option for scoring search results. Tesserae scores currently rate rare words shared between two texts as more likely to constitute an allusion. This is problematic for capturing allusions from Vergil, who is known for combining common words in uncommon ways, in what ancient critics called a new form or affectation (cacozelia). The incorporation of comparative bigram frequencies can more accurately score allusions to Vergilian bigrams, which would otherwise be erroneously demoted. For example, if a search result is particularly indicative of the source author, but not of the corpus or target author, this might indicate that the target author is quoting a recognizable phrase. In this case, the Tesserae score should be increased. If the match is indicative of a target author’s shared language, but not of the corpus or the source author, it is less likely that the target author is trying to evoke the source author. In this case, the Tesserae score should be decreased.
Many studies from the 1990’s on have shown the efficacy of analyzing word co-occurrence patterns in English. In 2000, Rydberg-Cox adapted existing methods for ancient Greek as a basis for philological research. PMI values represent a ratio of “actual” versus “expected” frequency with which two words appear near each.
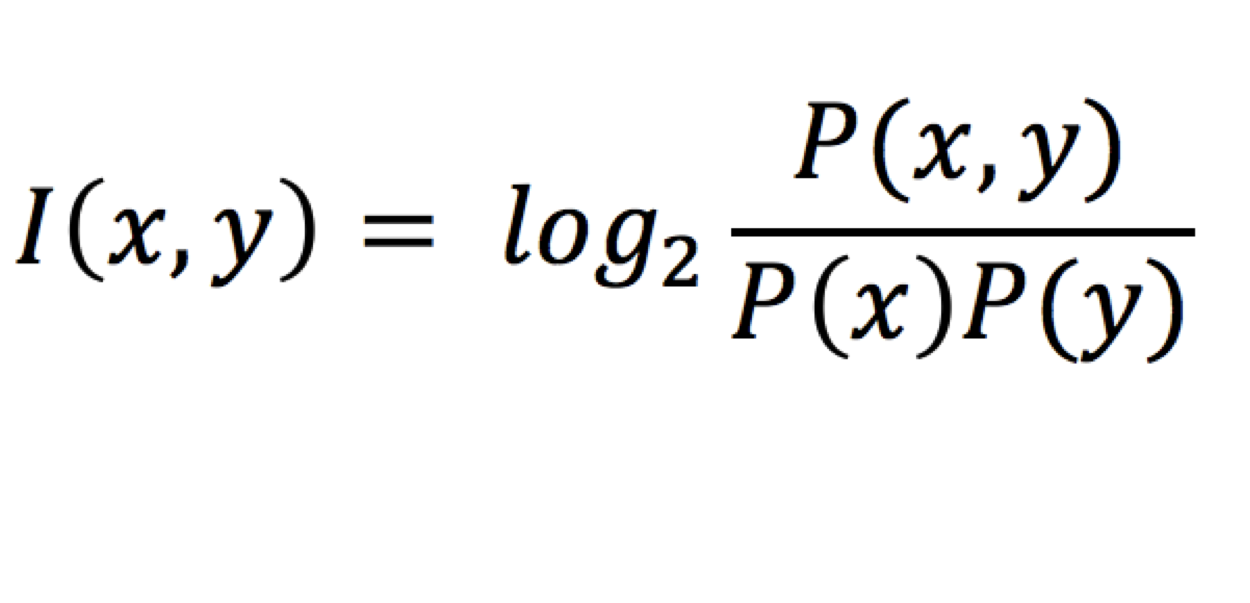
The actual frequency of a bigram is a measurement of the frequency with which a combination of words x and y occurs. The expected bigram frequency is a measurement of the frequency with which words x and y might have occurred as a bigram based on the frequencies of its constituent unigrams. This represents the bigram frequencies we would see if the distribution of each word were independent of the distribution of the other. In reality, contextual and syntactic relationships change the likelihood that word y will follow word x, and so the actual and expected frequency values diverge. Finally, because PMI overemphasizes low-frequency collocations, it is standard practice to cut off extremely rare words and to log and normalize the results.
Results from the Aeneid and the corpus are then normalized so that PMI values can be meaningfully compared. Normalization translates the scale of the PMI values from Vergil and from Latin epic authors to a range from -1 to 1. Positive PMI values indicate that once you read one word in Vergil, the uncertainty of the next words dramatically shrinks. Negative PMI values indicate that the presence of one word in Latin epic negligibly affects the possibility pool for the next word.
Consider the following example of a high PMI value from Vergil’s Aeneid 12.338: fumantis sudore quatit, miserabile caesis. Fumantis sudore describes horses frothing with sweat, and has a normalized PMI score of 0.684. Since PMI values for Vergil indicate that fumo usually occurs with incense, altars, food and homes, and sudor usually occurs with people, blood, and labor, fumantis sudore is “marked” or unusual phrase in Vergil. Since fumantis sudore is not a high ranking result in the PMI values of the Latin epic corpus, it is further likely to be an example of particularly “Vergilian” language.
The following graph shows the PMI values for Vergilian bigrams that also exist in the epic corpus. Most of the PMIs are positive, indicating strong associations between words. The data with the highest PMI values represents the strongest word associations in Vergil.
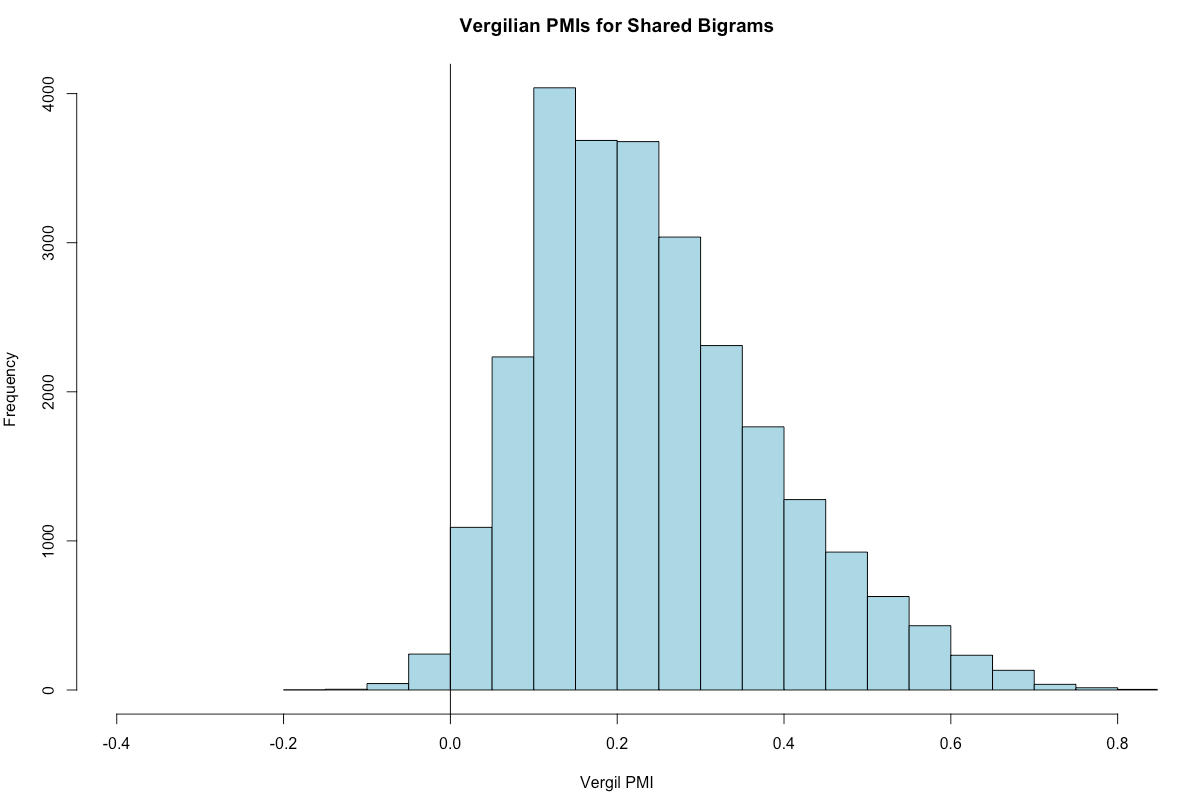
The next graph shows the PMI values for bigrams in the epic corpus that also exist in Vergil. Here, the PMIs are mostly negative. This indicates that in epic as a whole, word association is more flexible than in Vergil alone.
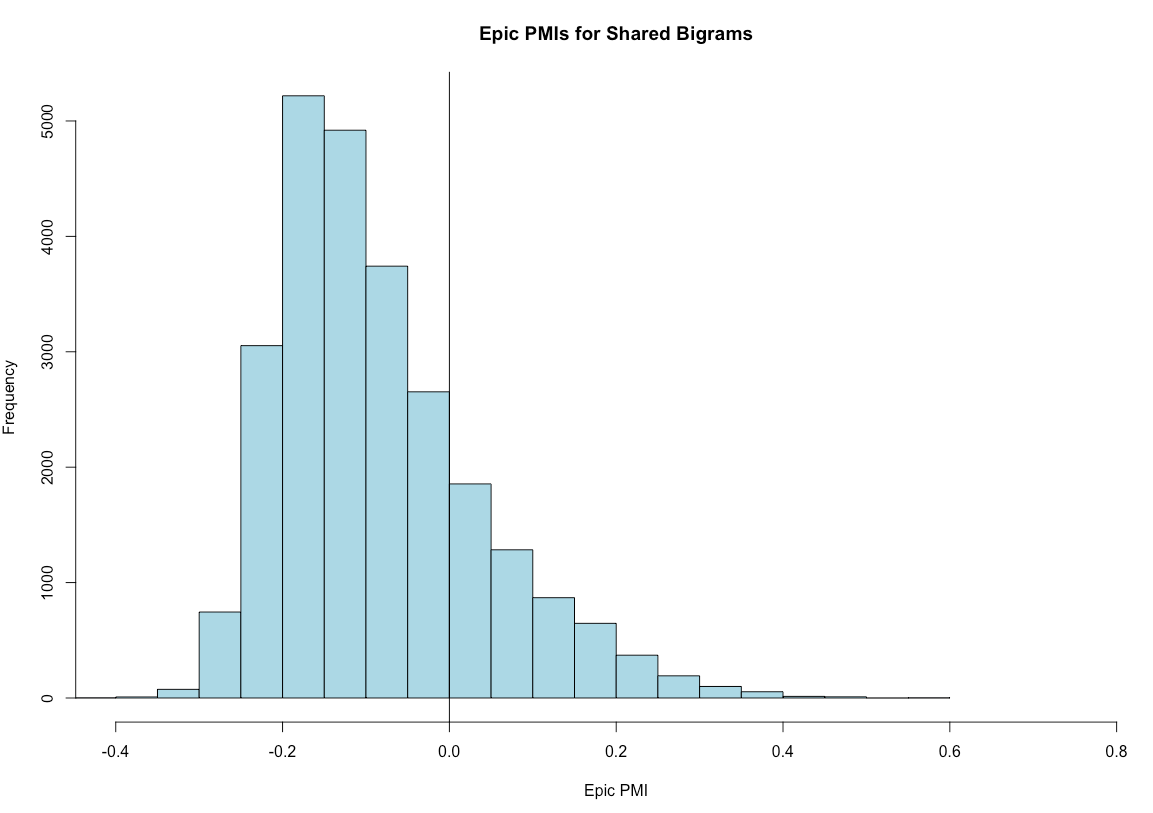
These graphs indicate that Vergil’s word associations as different from those in the epic corpus generally. For example, Vergil’s normalized PMI for aequore~toto is about 0.5, occurring 6 times. In the rest of Latin epic, aequore~toto appears 9 times and has a normalized PMI of 0.03. The difference is that in Vergil, aequore expects toto, whereas is in epic generally, aequore does not prime the reader to expect toto.
The data does not tell us which author differs from the corpus more dramatically – other normalization factors will have to be put into place before we can compare, for example, Vergil’s distance from the corpus to Lucan’s distance from the corpus. Beyond its applications for Tesserae, co-occurrence patterns can improve our understanding of what phrases are more striking or marked than others, and of what constitutes the recognizability of an ancient author’s hand.