
Harry Diakoff has shared with us a set of Greek synsets—groups of words purported to be mutually synonymous—while Tesserae has an algorithm which is supposed to measure semantic similarity between any two words. While both approaches ultimately are based upon the Perseus XML version of the Liddell-Scott-Jones lexicon, they employ very different methods. We hope that by comparing the two we can improve upon both.
Synsets
I don’t really know how these were created—maybe by translating entries in the English WordNet? Harry, can you fill in any details here? The important characteristics of the synonym sets are:
- each set has a unique id
- within a set, all relationships are presumed to be mutual and symmetrical
- words can belong to more than one set
Similarities
Tesserae calculates word similarities using the Python topic modelling package Gensim. We treat every entry in LSJ as a “document,” which is digested to produce a bag of English words used in defining the Greek headword. These English words are TF-IDF weighted and used to create a feature vector describing the headword. Headwords are compared using gensim.similarities.Similarity()—for any query word this returns a score between 0 and 1 for every other word in the corpus. In addition to this absolute similarity score, we can also sort all results by score and consider the rank position of a given result some measure of its relationship to the query word.
- each pair of words has a unique similarity score
- some words within a synset can be more alike than others;
- but homonyms are flattened
- this similarity is symmetrical, but the rank positions aren’t:
- the rank of result B given query A is not the same as that of A given B
You can see the code I used to calculate these metrics in the synonymy directory of the tess.experiments git repository. But please be patient—it’s still quite rough; please feel free to improve it…
Current problems
Both of these datasets have their difficulties. Each set is probably missing some headwords. The synsets include some false positives and negatives. The similarity scores can’t be turned into lists of synonyms without a threshold—either a similarity or rank position—that defines synonymy.
Ultimately, we need ground-truthing. What follows is merely a first attempt to compare the two approaches and figure out to what degree they are in agreement, and to get some ideas about where and in what ways they differ.
A first glance
What I’ve done here is to break Harry’s synsets down into pairwise relationships, and then measure similarity and rank position (in each direction) for all of the pairs that exist in the Tesserae similarity matrix.
Harry sent us 17,342 synsets, which decomposed into 235,702 unique pairs of words. Of these, 174,816 pairs returned results from a Tesserae similarity query. In the remaining cases, one or both of Harry’s words didn’t exist in our corpus. Although we both used the same dictionary, we each had our troubles reading it; more about this in another post.
Initial results look like this:
| KEYPAIR | SIM | RANKA | RANKB | SYNSETS |
|---|---|---|---|---|
| θαλασσουργία->ἁλιεία | 0.522157 | 71 | 216 | 454121;453935 |
| κόπρος->σπατίλη | 0.301455 | 38 | 55 | 14853947 |
| συμπάρειμι->ἔησθα | 0.239762 | 228 | 136 | 4353803;7959016;5861067;… |
| τρωπάω->ἐξυπτιάζω | 0.139253 | 1250 | 1090 | 346532;7423365;457382;… |
| κηλιδόω->μελαντήριονστίγμα | None | None | None | 6794666 |
SIM gives the similarity score for each pair; RANKA gives the rank position of the righthand member among results when the lefthand member is used as the query; RANKB, the rank position of the lefthand member when the righthand one is the query; and SIMSETS gives the id number(s) of synsets in which this pair appears. In the bottom row you see what happens when Tesserae can’t find one or both of the words—in this case it seems that one member of the pair is actually a phrase, although there are other cases where Tesserae can’t find a word that clearly should be in the dictionary. You can download the full dataset here.
Similarity and synonymy
Given that all the word pairs extracted from the synsets are supposed to be synonyms, and that similarity is supposed to be a measure of synonymy, we might hope that most of the pairs will have high SIM scores. This didn’t turn out to be the case: while a significant number scored 1, the majority of the pairs scored 0; among the rest, there seemed to be preference for low scores over high.
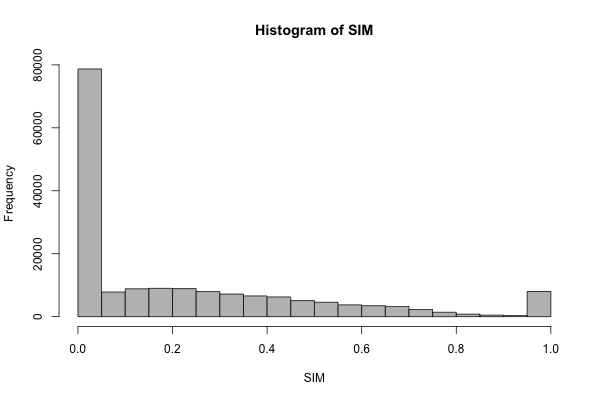
Rank position and synonymy
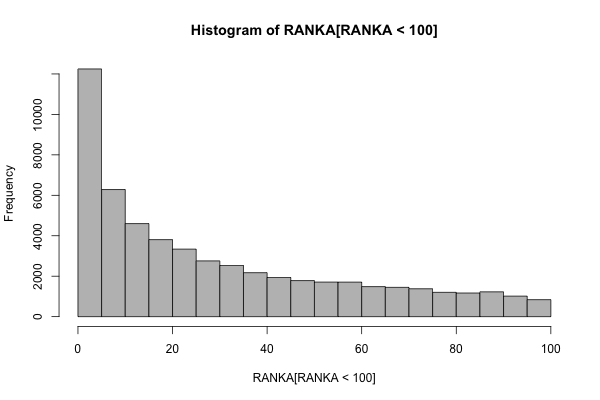
On the other hand, rank position did better. I added together RANKA and RANKB to flatten out weird asymmetries for now, and found that a large majority of word pairs had high ranks:
![]()
It seems safe to say we’re not interested in results that ranked 50,000th in an ordered list of most similar words. Here’s a closeup of just the top-ranked (i.e. furthest left on the x-axis) according to RANKA only. It does pretty much what we had hoped for:
So it seems on a first pass as though rank is working out of the box, while similarity needs work. What if we use rank as a filter on similarity? Here is the distribution of similarity scores among pairs whose combined RANKA + RANKB is less than 100. Not only are these pairs high ranking, but they’re also relatively symmetrical, given that the two ranks can differ by no more than 99 in each case. Here, the huge spike at SIM=0 is gone; the spike at 1 is preserved, and the rest form a nice curve around the middle of the similarity spectrum.
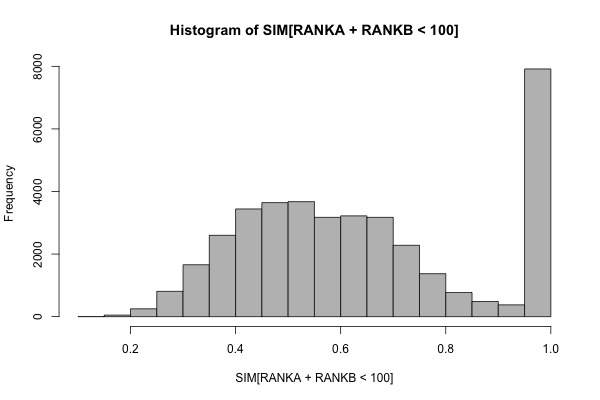
Clearly more work to be done here, but this seems to be an exciting start!