
At the end of the first century, Quintilian asked “Is it not sufficient to model our every utterance on Cicero? For my own part, I should consider it sufficient, if I could always imitate him successfully. But what harm is there in occasionally borrowing the vigour of Caesar, the vehemence of Caelius, the precision of Pollio or the sound judgment of Calvus?”
As philologists of the 21st century, we might ask “How often did Roman authors actually borrow phrases from Caesar as opposed to Cicero?”
Caitlin Diddams and I recently published an article in Digital Scholarship in the Humanities which lays out the best practices for determining:
- Which phrases shared between two authors did not come from a second possible source
- How to measure the relative strength of an “intertextual signal”
- How to compare the relative influence of multiple authors on a cross-section of literature
As a test-case, we compared the influence of Cicero and Caesar during the early imperial and late imperial periods.
The methodology we outline in this article can be used on any number of source and target authors, regardless of language. Our formula for calculating the strength of an intertextual signal can be used with any tool for detecting intertextuality (not just Tesserae).
To read the abstract and obtain the full article, visit the Oxford Journals website: https://academic.oup.com/dsh/article-abstract/doi/10.1093/llc/fqx038/4061474/Comparing-the-intertextuality-of-multiple-authors
Relative influence in our methodology is compared according to the ‘rate of intertextuality,’ which is a normalized representation of the number of results you get in a Tesserae search. Normalization is necessary because the length of a work influences the number of results obtained. Previous methods of normalization assumed that Tesserae’s scoring algorithm would perform consistently across various authors and genres of literature. We propose that best practice should avoid such assumptions wherever possible.
Our normalization method in brief (the following is excerpted from a pre-print copy of the article):
The number of results of two searches cannot be meaningfully compared until we consider how many results each search could have produced. The number of search results depends on two factors: the level of engagement between the authors and the length of the texts being compared. Longer texts create more sentence-by-sentence comparisons. There are more opportunities for unique intertexts to occur. The number which can be meaningfully compared is not the number of unique results of a Tesserae search, but the ratio of the results found to the results that could have been found. We normalize the number of results according to the following formula:
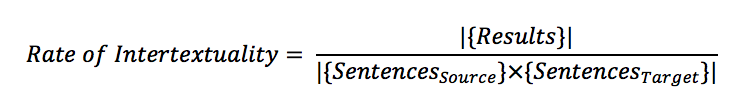
We define the rate of intertextuality as the number of connected phrases per pair of phrases considered. This is derived by dividing the absolute value of the set of results by the absolute value of the cross-product of the sets of sentences in source and target texts. This cross-multiplication is necessary because Tesserae compares every sentence in a source text to all of the sentences in a target text.6 Therefore the number of possible results in a comparison of any source and target is the product of the number of sentences in the source and the number of sentences in the target.