
Notre thèse de départ s’appuyait sur le postulat que l’épopée et l’élégie emploient un langage différent, et que la présence de quelques traits distinctifs de chacun de ces genres dans le 1er livre de l’Achilléide montrerait la nature génériquement hybride de ce poème. Nous nous sommes inspirés entre autre du chapitre de Francis Cairns, «Dido and the Elegiac Tradition» où Cairns évalue les éléments spécifiques au lexique et aux topiques élégiaques du quatrième livre de l’Enéide. Ici, nous nous proposons d’examiner les traits généraux de la langue de l’Achilléide et de les comparer aux traits de la langue employée par les autres textes de notre corpus, à travers des données statistiques à large échelle. Il ne s’agit pas, à ce stade, de relever des allusions spécifiques du texte-cible au texte-source.
Early in this course, we considered the hypothesis that elegy and epic employ different poetic languages, and that the first book of the Achilleid might reveal its intertextual relationships to these two genres by the ways in which it re-uses the distinctive elements of each. In this approach we were inspired by, among other things, our reading of Francis Cairns’ chapter “Dido and the Elegiac Tradition,” in which Cairns interprets the presence of elegiac diction in Aeneid 4. In this and future posts we will explore some simple ways to test our hypothesis, demonstrating some simple methods in which we can compare the language employed by the Achilleid with that of the other works in our corpus of source texts. As a complement to our close reading, however, here we will be looking at large-scale statistical properties rather than specific borrowings.
Construire un feature set des fréquences
Nous avons commencé par calculer les fréquences de tous les mots du corpus. Par exemple, moenia se trouve dans le texte à un taux moyen de 0.76 fois sur 1000 mots dans les textes épiques, mais à un taux de 0.10 sur 1000 dans les textes élégiaques. Le mot puella par contre, apparaît beaucoup plus fréquemment dans l’élégie, à un taux de 1.33 fois sur 1000 mots versus 0.01 dans les épopées.
We begin by calculating the frequency of every word in our corpus. For example, moenia occurs on average at a rate of 0.76 times per 1000 words in our epic texts, but at a lower rate, 0.10 times per 1000 words, in elegiac texts. On the other hand, puella occurs much more frequently in the elegiac portion of our corpus, at a rate of 1.33 times per 1000 words versus 0.01 in the epics.
| épopée | élégie | différence | |
|---|---|---|---|
| moenia | 0.76 | 0.10 | +0.66 |
| puella | 0.01 | 1.33 | -1.32 |
Après avoir calculé ces fréquences pour chaque mot du corpus, nous avons considéré la différence entre leur fréquence dans l’épopée et dans l’élégie comme un indice approximatif pour détecter les mots spécifiques de chaque genre.
Once we have calculated the frequency of every word in corpus, we can then take the difference between the average rate in epic and that in elegy as a rough measure of how distinctive a given word is: strongly positive values tend to be epic, strongly negative ones, elegiac.
| plus épiques | |
|---|---|
| et | 9.56 |
| iam | 2.55 |
| atque | 2.01 |
| ac | 1.15 |
| sub | 1.11 |
| tunc | 1.04 |
| haud | 0.96 |
| sanguine | 0.93 |
| arma | 0.86 |
| ora | 0.82 |
| plus élégiaques | |
|---|---|
| est | -8.05 |
| non | -5.35 |
| tibi | -4.52 |
| ut | -3.52 |
| quod | -3.48 |
| illa | -3.3 |
| nec | -3.07 |
| mihi | -2.96 |
| amor | -2.89 |
| si | -2.8 |
On remarque que, alors que des mots thématiques comme amor et arma apparaissent parmi les mots les plus spécifiques, la plupart est constituée de mots banals et fréquents comme et, iam, et est, qui ne concernent pas le contenu des poèmes. En fait, on sait bien que ces «mots-outils» sont indicatifs du style de l’auteur. A cet effet, il est essentiel de rappeler que notre corpus est restreint, et que les traits propre à l’auteur, en particulier ceux d’Ovide, peuvent masquer les signes génériques que nous cherchons.
It is interesting to note that while we do find thematic words like amor among the most distinctive words, for the most part the characteristic words are common, boring words like et, iam, and est, seemingly unrelated to the content. In fact, it has long been known that such “function” words are in fact strongly connected with authorial style, and so it’s important for us to remember that with such a small corpus, authorship will be a confounding factor. Keeping this in mind, we can go on to describe each work in the corpus by the frequencies of its words.
Comparer les textes
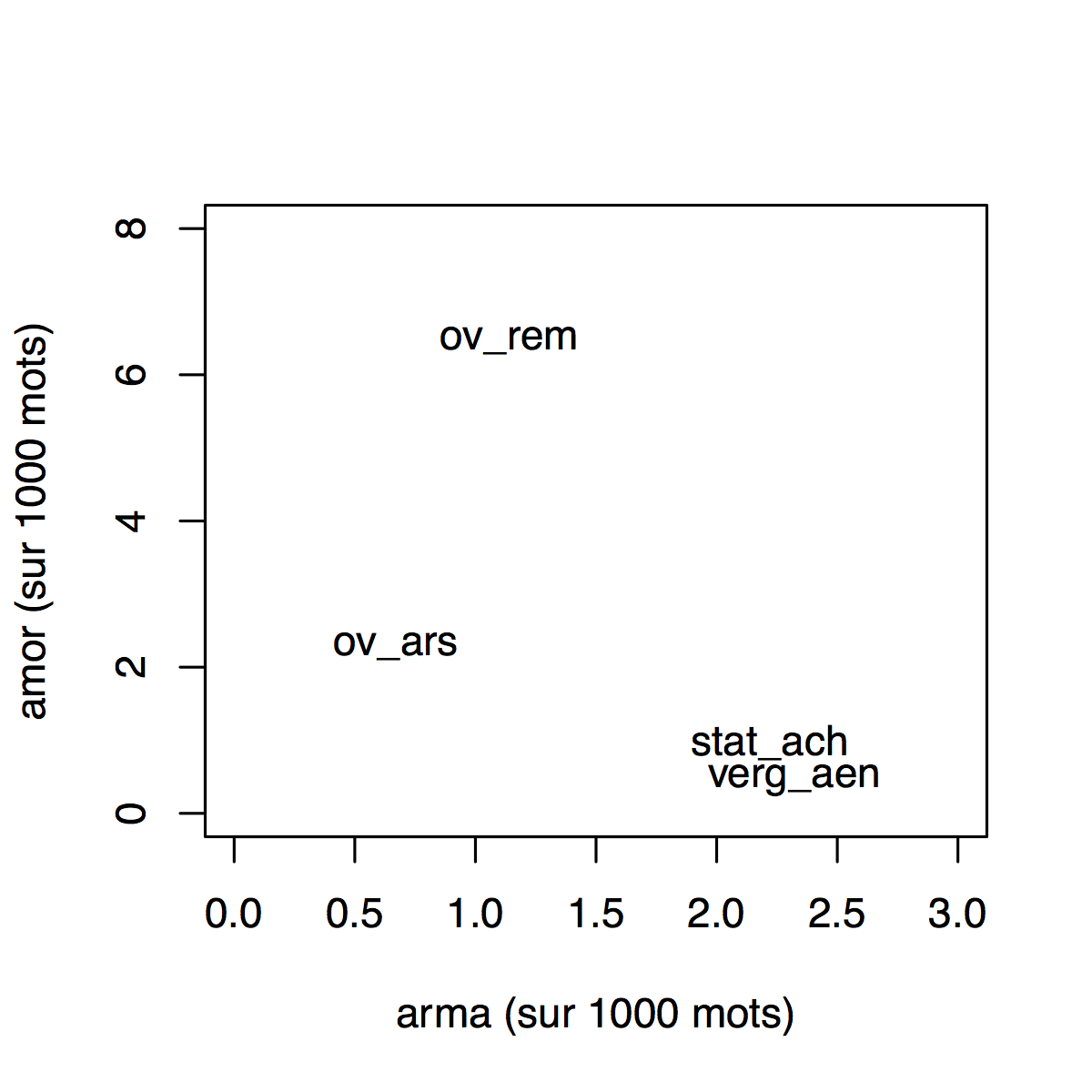
Chaque texte, donc, peut se définir comme un vecteur de fréquences ou comme un point dans un espace cartésien, ayant ces fréquences pour coordonnées. Par exemple, envisageons un petit corpus de deux textes épiques et deux élégiaques, en considérant seulement les fréquences des mots amor et arma. On placera chaque texte dans un graphique où la fréquence de arma détermine sa position sur l’abscisse et la fréquence de amor définit sa position sur l’ordonnée.
Each work in the corpus can thus be described as a vector of word frequencies, like a point in cartesian space with these frequencies as its co-ordinates. For example, consider two epic and two elegiac texts, represented by the frequencies of the terms amor, and arma. We can imagine placing each text on a graph where the frequency of arma, say, becomes its position on the x-axis, and that of amor its position on the y-axis.
| amor | arma | |
|---|---|---|
| stat_ach | 0.97 | 2.22 |
| verg_aen | 0.46 | 2.32 |
| ov_ars | 2.28 | 0.67 |
| ov_rem | 6.47 | 1.14 |
Dans ce petit exemple on voit que, en ce qui concerne ces deux mots, l’Achilléide est beaucoup plus proche de l’épopée de Virgile que des élégies d’Ovide.
In this toy example, we can see that, at least as far as these two words are concerned, the Achilleid is a lot closer to Virgil’s epic than it is to Ovid’s elegies.
Visualiser le corpus
Ensuite, nous pouvons considérer l’intégralité des coordonnées; une méthode qui s’appelle «principal components analysis» (PCA) nous aide à visualiser les textes en plus de 2 dimensions. PCA transforme systématiquement les données pour que la plus grande variance entre les points se situe dans la première coordonnée (PC1), la seconde plus grandes dans la deuxième (PC2), et cetera.
Finally, we can consider the full set of coordinates; a technique called principal components analysis, or PCA, will help us to visualise the texts in more than two dimensions. PCA performs a systematic transformation on the data so that the greatest variance among the points occurs in the first dimension (PC1), the second greatest variance in the second (PC2), and so on.
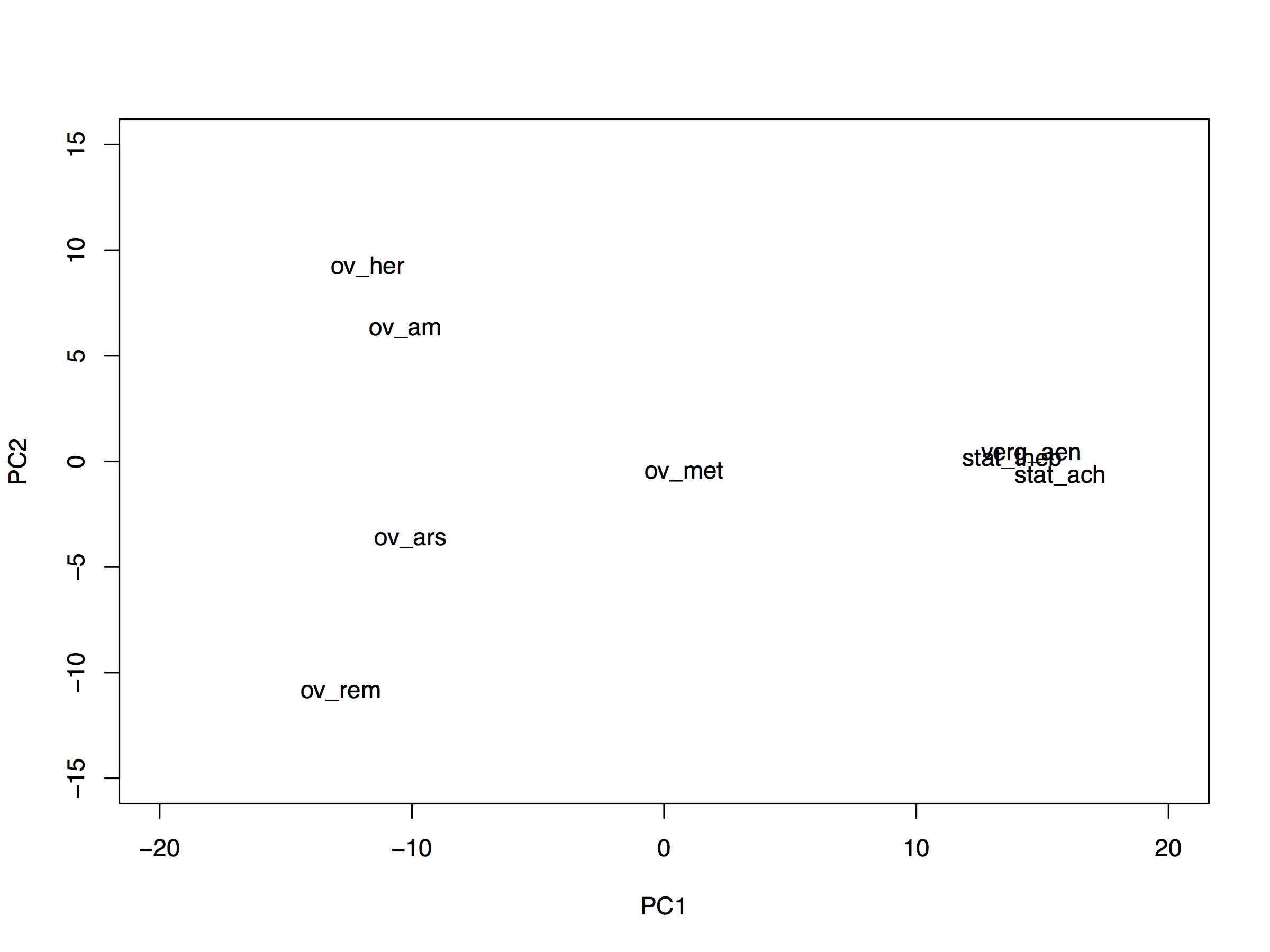
Voici, donc, les textes de notre corpus disposés sur PC1 et PC2: ces coordonnées ont été calculées d’après la totalité des fréquences (21,000). D’une part, nous constatons que sur l’abscisse (PC1) les épopées de Virgile et de Stace se regroupent du même coté du graphique, alors que les élégies se placent de l’autre; il est également intéressant de remarquer que l’épopée d’Ovide se trouve exactement entre les deux. D’autre part, l’ordonnée (PC2) montre une grande variété stylistique chez Ovide, contrairement à ce que l’on constate pour les autres auteurs épiques, même s’il ne faut pas perdre de vue que le grand nombre de textes ovidiens peut biaiser l’analyse PCA et maximiser les différences entre les textes. Comme dans l’exemple précédent, l’Achilléide se trouve très proche des autres épopées.
Here, then, are the texts of our corpus, shown according to PC1 and PC2, which are derived, to a greater or lesser degree, from the full set of 21,000 word frequencies. In the horizontal dimension, we see Virgil and Statius clustered at one side of the graph and Ovid’s elegies at the other; interestingly, Ovid’s sole epic poem is found right in the middle of these otherwise distinct groups. In the vertical dimension, on the other hand, we find that Ovid’s works display a stylistic diversity that we don’t see among the other texts. As we cautioned above, though, it’s important to consider that the large number of works by Ovid here could bias the PCA towards maximising their differences. Again, as in the earlier, toy example, the Achilleid groups closely with the other epics.
For further general information on authorship attribution and stylometry, a good free resource is Patrick Juola’s survey here.