As explained by Chris Forstall in his earlier post, we are currently experimenting with a new cross-language detection feature over on the Tesserae Development server. We are using two different approaches, and the naïve Bayesian alignment approach bears a little explanation. The purpose of this post is to provide a simple introduction to the theory behind the algorithm; a link to my PERL script which aligns two texts in Tesserae format will be provided at the end.
To begin with, let’s assume we have a corpus which consists of the same text in two languages. Let’s further assume that our texts are perfectly aligned, sentence-by-sentence (the difficulty of finding texts like this has led us to use the New Testament for our experiments). We want to know which word in language A corresponds to which word in language B. Initially, we assign each word an equal probability. Here’s a simple example sentence in Greek and Latin:
| Sentence A (Language A) |
Sentence B (Language B) |
| Amo libros legere |
Φιλω βιβλους ἀναγιγνωσκειν |
We’re going to try to figure out which word is a translation of Amo. First we assign an equal probability to all translation candidates. Because there are three words in Sentence B, the probability that Amo corresponds to Φιλω is 0.33, and the probability that it corresponds to βιβλους is also 0.33 (remember that a probability of 1.0 means that something is definitely true). The key to correctly lining up Latin words with their Greek translations is repetition. Let’s add another aligned sentence to our comparison:
| Sentence A (Language A) |
Sentence B (Language B) |
| Amo philosophiam |
Φιλω φιλοσοφιαν |
This time, the sentence from language B doesn’t contain βιβλους or ἀναγιγνωσκειν, so it’s less likely that either of those are legitimate translations for Amo. Φιλω has also appeared again, so the probability assigned to a possible Amo/Φιλω alignment is increased.
The equation that smooths out the probabilities of each conceivable alignment over the course of many, many sentences is called Bayes’ theorem. It looks like this:
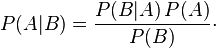
Here’s what the first part, P(A|B), means to us: “the probability that word A in language A is a correct translation of word B in language B.” The next part, P(B|A), means “the probability that word B in language B is the correct translation of word A in language A.” You’ll notice that putting these two statements on opposite sides of an ‘equals’ sign looks a little like circular logic. The key here is that Bayes’ theorem works backward in order to more appropriately weight the probability associated with each possible translation candidate. This will become clearer in the next paragraph. The rest of the equation has to do with ‘smoothing’ the results; remember that our goal is to correctly weight these probabilities according to the pattern which emerges through repetition. The next two parts, P(A) and P(B), mean, for our purposes, “the probability of word A occurring in language A” and “the probability of word B occurring in language B.” For these probabilities we substitute “the number of occurrences of word B in the ‘language B’ (or word A in the ‘language A’) text, divided by the total number of words in that text.”
Because Bayes’ theorem works backward from translation to antecedent, the application of this theorem in text alignment can look a bit complicated. This is how it works: to determine P(A|B) for any given Latin word, the program looks at all the sentences (actually Bible verses in our corpus) which contain that word. We’ll call this Verse Group 1. The program then gathers up all the Greek words in the corresponding Greek verses. These Greek words are our translation candidates, and we look at each of them in turn. To calculate P(B|A) (the probability of the original Latin word, given the current Greek translation candidate), the program looks at all the Greek verses which contain the translation candidate. We can call this group of verses ‘Verse Group 2.’ The program then gathers up all the Latin words in the Latin versions of Verse Group 2. The important factor here is that we’re grabbing a different set of verses than those in Verse Group 1. The amount of overlap between Verse Group 1 and Verse Group 2 depends on how good a translation candidate we’re looking at. In other words, when we look back from Greek to Latin, we may find verses that don’t contain the original Latin word under scrutiny. This is especially true if the Greek translation candidate is not actually the word we ultimately want; if we are looking at the wrong Greek word, we’ll end up gathering a bunch of Latin verses which don’t contain our original word and that will lower the value of P(B|A).
The rest of the program is what my high school Physics teacher used to call “plug and chug.” ‘Probabilities’ are really just the number of times that a given word appears divided by the total number of words in the group in which it appears. An important feature of this approach is that for each word we examine, the program returns the probability of an alignment between that word and each possible translation word–just like in the first set of sentences at the top of this post. Many tools for this type of operation can be found online; a popular one is mGIZA. My own code for this project can be found on github.
Feel free to ask questions or leave feedback in the comments section.
